The post by “Prime Video” initiated a few misleading posts where some people are claiming “Microservices are evil” and arguing to move to Monolith. But before we state any argument, we need to understand the problem so that we can better understand the solution. The problem they had with the current architecture is twofold, Cost effectiveness and scalability. And the solution target those problems.
My view on this incident is to understand what we can learn from it. In this post, I am not intending to dissect their post. But for reference here is the previous architecture that they had. Now let’s try to see what they did and understand their initial goal.
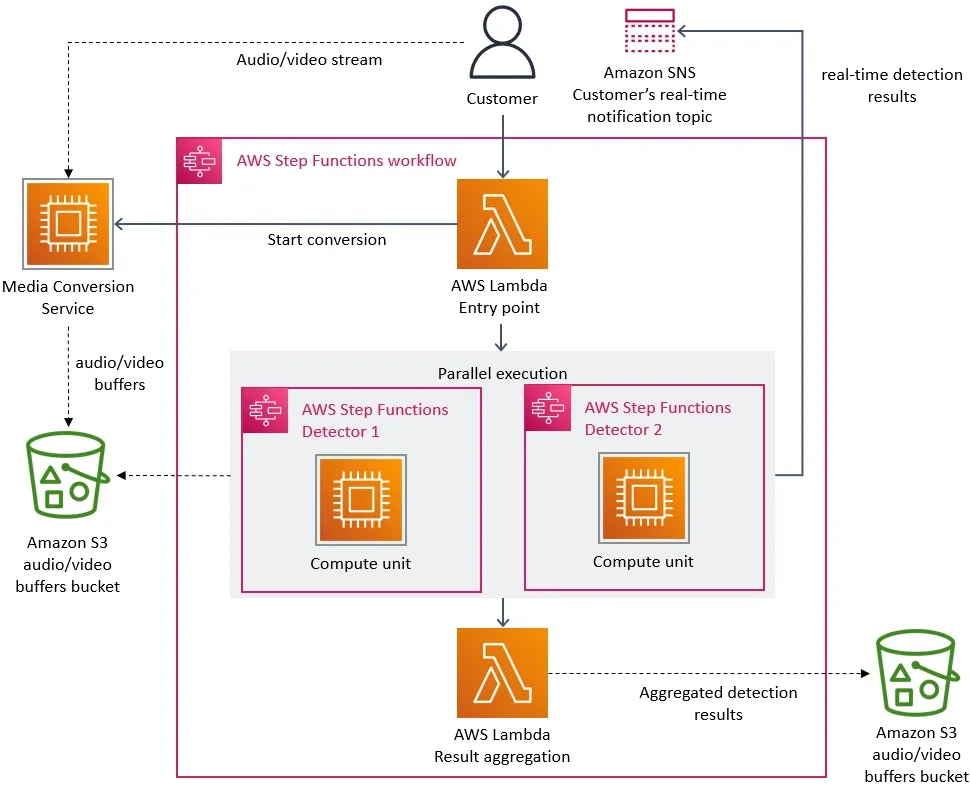 Previous architecture
Previous architecture
From an architecture point of view, this looks nice. They have a serverless implementation so that they can scale very quickly. Step functions allow you to see the progression of the process nicely. If the data is stored on S3(multi region), they can use the Lambda@Edge and then the computation can be close to distribution, which would be ideal. But there are significant disadvantages to using Lambda. Lambda Edge is available in limited distribution. It can have a cold start time which is not appropriate for a real-time operation. If we use do not use Lambda edge then the data moves around the world and for use case like Prime video it is not appropriate. Now however I look at it the previous architecture was not built to have the scale(globally) and the cost in mind in the first place. Now I think that is a huge learning for me. It is really important to understand the problem that you want to solve before planning on a solution. Sometimes we feel the urge to do something and show. Without clarity of the problem I might think of prototyping to understand the problem better. And there can be a form of iteration on that.
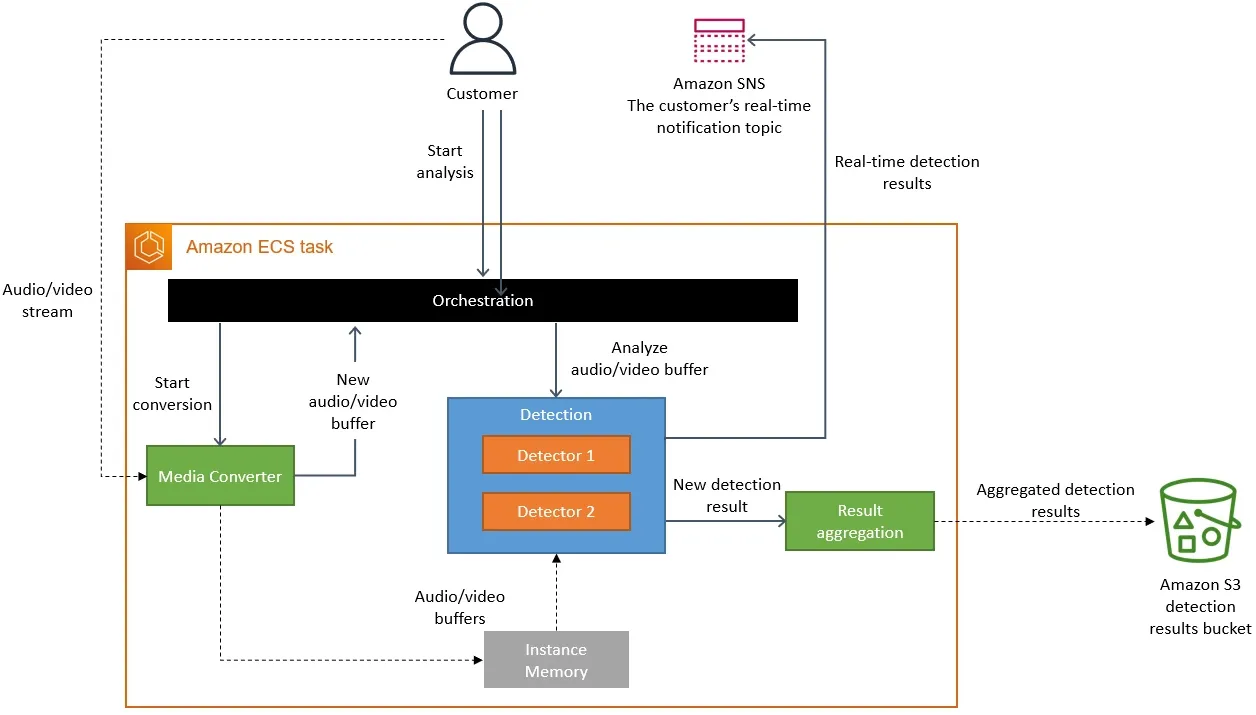 New architecture
New architecture
In the new solution,
- No cold start
- Can be deployed in more regions
- The large data is transferred through memory
The media converter needs to work on streams and anomaly detection has to be on the converted stream. I am not sure what they are using but seems like a classical use case of stream processing framework, like Spark. As the streams would be cached close to distributions close to clients, any processing needs to happen closer to the distribution to reduce latency and data transfer over network. Now merging lambda’s into a single service is not a process I would label as Microservices to Monolith. But I can relate that media conversion and anomaly detections are two different concerns. So I would package the both in different dev env/repo but orchestrate on the same server. So I would say the learning for me is to think about the production environment. Only thinking about logical application boundaries might not be efficient always.